



오백만년만에 알고리즘 풀러 와서 대략 10번 넘게 시간초과와 삽질한 후기
서론
굉장히 오랜만에, 친구가 알고리즘을 풀고 있길래 심심해서 Kotlin/JVM 으로 도전해본 2751 번 '수 정렬하기 2' 문제다.
문제 설명을 대략 보면:
시간 복잡도가 O(nlogn)인 정렬 알고리즘으로 풀 수 있습니다. 예를 들면 병합 정렬, 힙 정렬 등이 있지만, 어려운 알고리즘이므로 지금은 언어에 내장된 정렬 함수를 쓰는 것을 추천드립니다.
라고 적혀있다. 아마 조건에 적혀있는 100만개의 수가 진짜로 주어질 터이다.
요약하자면, 메모리 절약을 위해 IntArray.sort() 를 사용하면 시간 초과로 틀린다.
그냥 생각없이 MutableList.sort() 를 사용해야한다. 그 이유를 대략 알아보자.
IntArray.sort() 와 MutableList.sort()
Kotlin/JVM 에서:
IntArray는 Java ByteCode 로 보았을 때int[]이고,MutableList<T>는List<T extends Comparable<? super T>>이며 정렬 시 내부적으로Object[]로 변환된다.
즉, IntArray 는 int[] 로서 정렬이 이루어지고, MutableList<T> 는 Object[] 로서 정렬이 이루어진다. 두 정렬의 차이를 보자:
public static void sort(int[] a) { DualPivotQuicksort.sort(a, 0, 0, a.length); }
Arrays.java
public static void sort(Object[] a) { if (LegacyMergeSort.userRequested) legacyMergeSort(a); else ComparableTimSort.sort(a, 0, a.length, null, 0, 0); }
Arrays.java
요컨데, int[] 는 DualPivotQuickSort 를 사용하고, Object[] 는 ComparableTimSort 를 사용한다.
두 클래스의 정의로 가서 클래스 설명을 한 번 살펴보자.
각 경우의 시간복잡도
/** * This class implements powerful and fully optimized versions, both * sequential and parallel, of the Dual-Pivot Quicksort algorithm by * Vladimir Yaroslavskiy, Jon Bentley and Josh Bloch. This algorithm * offers O(n log(n)) performance on all data sets, and is typically * faster than traditional (one-pivot) Quicksort implementations. * ... * @author Vladimir Yaroslavskiy * ... */ final class DualPivotQuicksort { }
DualPivotQuickSort.java
일단 이라고는 적혀있다. 다음은 TimSort 를 한 번 보자.
/** * A stable, adaptive, iterative mergesort that requires far fewer than * n lg(n) comparisons when running on partially sorted arrays, while * offering performance comparable to a traditional mergesort when run * on random arrays. Like all proper mergesorts, this sort is stable and * runs O(n log n) time (worst case). In the worst case, this sort requires * temporary storage space for n/2 object references; in the best case, * it requires only a small constant amount of space. * ... */ class TimSort<T> { }
TimSort.java
얘도 일단 이라고 적혀있다. 둘이 같은거 아닌가?
도와줘!
나는 알고리즘을 열심히 한 사람이 아니기 때문에, Gemini에게 불어봤다:
DualPivotQuickSort와TimSort각각의 최악의 케이스에 대해 시간복잡도와 연관지어 설명해줘
이렇게 물으면 대략 이런 대답을 해준다:
DualPivotQuickSort는 피벗이 두 개이므로 데이터를 3등분하여 처리하지만, 선정된 피벗이 한쪽에 쏠린 데이터인 경우 분할한 의미가 없어지고 데이터의 수 만큼 분할()할 가능성이 있습니다.
그러나TimSort는MergeSort기반에InsertionSort를 결합한 정렬이고, 무조건 둘로 나누게 되기 때문에 최악의 경우에도 이 유지됩니다.
우리가 알고있는 QuickSort 는 피벗 하나를 둔 후에 그보다 작은 값을 피벗보다 왼쪽에, 나머지를 오른쪽에 두는 방법으로 이 과정을 재귀적으로 반복하여 정렬하는 알고리즘이다.
그리고 익히 배운대로, QuickSort 는 이미 정렬된 배열에 대해 피벗을 항상 가장 작은 값을 고르게 되어 최악의 케이스를 보여준다.
그렇다면 DualPivotQuickSort 도 마찬가지인가? 다시 한 번 물어봤다:
DualPivotQuickSort도 이미 정렬된 데이터에 대해 최악의 케이스를 보여줘?
이렇게 물으면 이런 대답을 해준다:
DualPivotQuickSort도 피벗이 두 개라는 차이만 있을 뿐 비슷합니다. 피봇 선정 알고리즘에 의해 선택한 두 개의 피봇이 데이터에서 가장 작은 두 개의 값이었거나 가장 큰 두 값이었을 경우 발생합니다.
다만, 현대적인DualPivotQuicksort(Vladimir Yaroslavskiy 방식 등) 구현체는 이미 정렬된 데이터 등에 대한 감지/최적화 로직이 이미 포함되어 있기 때문에, 반드시 이런 경우가 최악인 것은 아닙니다.
즉, 모든 피봇선정 알고리즘을 분석하여 Anti-QuickSort 를 위해 만들어진 데이터의 경우 최악의 경우()가 될 수 있습니다.
즉, 장황하게 적었지만 정리하자면 DualPivotQuickSort 는 운나쁘면 이고, TimSort 는 항상 이라는 점이겠다.
그렇다면?
과거의 나였다면 실제로 100만개의 데이터가 대략 어떻게 생겼을지 만들어보거나, DualPivotQuickSort.java 의 구현을 살펴보면서 분석해봤겠지만, 낡고 지친 직장인인 현재의 나는 이럴 기력이 없다.
편하게 살자:
- 정석:
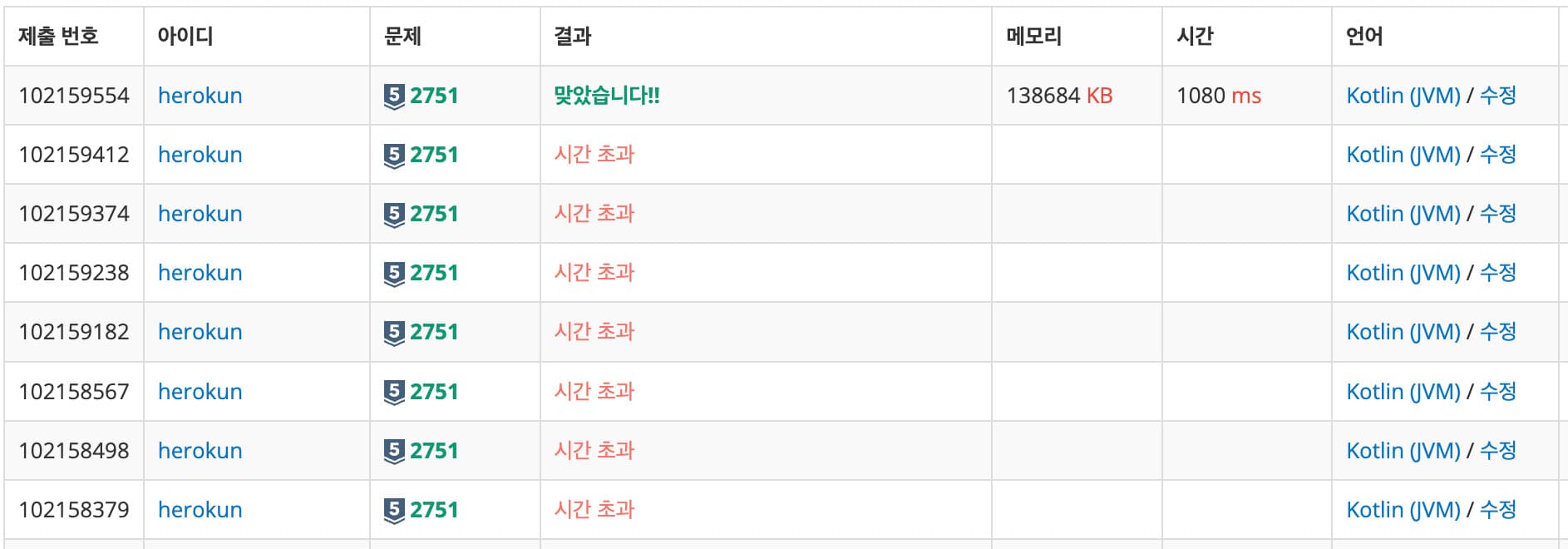
MutableList.sort()를 쓰자 - 154mb / 1250msMutableList(...) { ... }.apply { sort() }.forEach { ... } - 꼼수: 데이터가 못생겼다고? 그럼 섞어!! - 138mb / 1080ms
IntArray(...) { ... }.apply { shuffle() }.apply { sort() }.forEach { ... }
섞은 데이터가 이상하지 않다는 전제 하에, 메모리 사용량과 시간을 보면 DualPivotQuickSort가 더 우월하다.
그러나 물론 이상하지 않은 데이터를 섞어서 이상한 데이터를 만들 가능성도 어쨌든 존재하고, 게다가 그 '최적의 케이스' 인 경우에도 DualPivotQuickSort는 이지만 TimSort 는 이다.
쉽게 보자면, DualPivotQuickSort 는 ~ 이지만 TimSort 는 ~ 이라는 것이다.
결론
이정도쯤 읽으면 그럼 DualPivotQuickSort 가 가지는 이점은 없는건지, 싶을 것이다.
물론 있다:
- 메모리 공간을 적게 먹는다. 위의 실행 결과는
stdin과stdout,String연산으로 인해 크게 비교가 안되지만, QuickSort 는 in-place 정렬 이므로 추가 메모리 공간이 거의 필요가 없다. - 배열을 스캔(Scan)하면서 피봇과 비교하는데, 이 짓이 CPU의 캐시 메모리 구조와 아주 조합이 좋다(Spatial Locality).
솔직히 잘 안와닿는 얘기이긴 하다. 어쨌든 나는 너때문에 시간초과를 10번이나 당했다고.
마무리는 Gemini 의 말을 인용하도록 하겠다:
왜 TimSort의 최적이 더 유리한가?
현실 세계의 데이터는 완전히 무작위(Random)인 경우보다, 어느 정도 정렬되어 있는 데이터가 많습니다.
QuickSort는 최적 상황이라도 데이터를 분할하고 다시 합치는 과정( 단계)이 필수적입니다.
TimSort는 이미 정렬된 데이터라면 분할/병합 과정을 건너뛰고 바로 완료할 수 있습니다.
즉, TimSort는 현실적인 데이터 상태를 활용하여 최적의 성능을 낼 수 있기 때문에 더 유리합니다.




